
Lately there has been a lot of discussion among insiders and those closely following the COVID “mRNA vaccine” story concerning contamination of the mRNA vaccines with DNA fragments which include DNA sequences derived from Simian Virus 40 (SV40).
Is this just another inside-baseball tempest in a teapot, akin to the various “social media expert/theorist”-promoted fringe conspiracy, fearporn-amplified controversies concerning graphene oxide , living hydras or snake venom in the vaccines, or that the lipid-pseudoRNA nanoparticles are actually 24th century Star-Trek science fiction nanobots which will reprogram all of our brains?
Is this DNA contamination/adulteration issue the real thing, one that should actually concern you – and the courts?
Drs. David Speicher, Kevin McKernan and colleagues are actually real-life, bona fide serious scientific and technical experts in real-world application of sequence and molecular biologic analysis methodology. It is what they do, day in and day out, for a living. Which happens to be the specific technical area which they are reporting on.
These are not fringe “fever swamp” conspiracy theorists (Steve Bannon’s term).
Dr. David J. Speicher, University of Guelph Department of Pathobiology, 50 Stone Rd E, Guelph, ON, N1G 2W1, [email protected] , ORCID 0000-0002-1745-3263
What Speicher et al are observing and reporting in this scientific manuscript linked below clearly demonstrates a profound failure of FDA and global regulatory authorities to do their most important job – to insure the purity and lack of adulteration of the pharmaceuticals which they authorize for marketing and use by physicians and allied health professionals.
At a minimum, it once again demonstrates the rampant willful blindness which seems to have pervaded the FDA/CBER vaccines branch under the “true believer” guidance of Dr. Peter Marks, who is neither a vaccine expert, nor an immunologist, nor a molecular biologist, nor someone who has any understanding of non-viral lipid nanoparticle-based polynucleotide delivery but rather is a clinical hematologist/oncologist who is the initial originator and continued proponent of the “operation warp speed” approach to vaccine (and now cancer drug) development. Which is to say bypassing almost all of the normal procedures and lessons learned from decades of development, manufacturing, approval for marketing and post-marketing surveillance of biological and drug products.
At worse, with this new information there is the appearance of a “smoking gun” demonstrating corrupt collusion between the US and other Western administrative states’ pharmaceutical regulatory authorities and the pharmaceutical industry.
Based on my personal assessment of these data, this contamination appears to meet the formal criteria for pharmaceutical “adulteration,” which is strictly prohibited by US federal law. The prevention of drug, device, and food “adulteration” is one of the central missions of the FDA – basically, a central reason that the FDA was created in the first place.
One key question which remains unresolved is how did this even happen?
Was this adulteration known by FDA, EMA, the Paul Ehrlich Institute, Health Canada etc. and hidden from the public? If not known, how did this adulteration escape detection by virtually all Western nation-authorized government regulatory experts?
Below is a screenshot of the tweet with a link to the associated pre-print manuscript which has launched this latest firestorm.

Abstract
Background: In vitro transcription (IVT) reactions used to generate nucleoside modified RNA (modRNA) for SARS-CoV-2 vaccines currently rely on an RNA polymerase transcribing from a DNA template. Production of modRNA used in the original Pfizer randomized clinical trial (RCT) utilized a PCR-generated DNA template (Process 1). To generate billions of vaccine doses, this DNA was cloned into a bacterial plasmid vector for amplification in Escherichia coli before linearization (Process 2), expanding the size and complexity of potential residual DNA and introducing sequences not present in the Process 1 template. It appears that Moderna used a similar plasmid-based process for both clinical trial and post-trial use vaccines. Recently, DNA sequencing studies have revealed this plasmid DNA at significant levels in both Pfizer-BioNTech and Moderna modRNA vaccines. These studies surveyed a limited number of lots and questions remain regarding the variance in residual DNA observed internationally.
Methods: Using previously published primer and probe sequences, quantitative polymerase chain reaction (qPCR) and Qubit® fluorometry was performed on an additional 27 mRNA vials obtained in Canada and drawn from 12 unique lots (5 lots of Moderna child/adult monovalent, 1 lot of Moderna adult bivalent BA.4/5, 1 lot of Moderna child/adult bivalent BA.1, 1 lot of Moderna XBB.1.5 monovalent, 3 lots of Pfizer adult monovalent, and 1 lot of Pfizer adult bivalent BA.4/5). The Vaccine Adverse Events Reporting System (VAERS) database was queried for the number and categorization of adverse events (AEs) reported for each of the lots tested. The content of one previously studied vial of Pfizer COVID-19 vaccine was examined by Oxford Nanopore sequencing to determine the size distribution of DNA fragments. This sample was also used to determine if the residual DNA is packaged in the lipid nanoparticles (LNPs) and thus resistant to DNaseI or if the DNA resides outside of the LNP and is DNaseI labile.
Results: Quantification cycle (Cq) values (1:10 dilution) for the plasmid origin of replication (ori) and spike sequences ranged from 18.44 – 24.87 and 18.03 – 23.83 and for Pfizer, and 22.52 – 24.53 and 25.24 – 30.10 for Moderna, respectively. These values correspond to 0.28 – 4.27 ng/dose and 0.22 – 2.43 ng/dose (Pfizer), and 0.01 -0.34 ng/dose and 0.25 – 0.78 ng/dose (Moderna), for ori and spike respectively measured by qPCR, and 1,896 – 3,720 ng/dose and 3,270 – 5,100 ng/dose measured by Qubit® fluorometry for Pfizer and Moderna, respectfully. The SV40 promoter-enhancer-ori was only detected in Pfizer vials with Cq scores ranging from 16.64 – 22.59. In an exploratory analysis, we found preliminary evidence of a dose response relationship of the amount of DNA per dose and the frequency of serious adverse events (SAEs). This relationship was different for the Pfizer and Moderna products. Size distribution analysis found mean and maximum DNA fragment lengths of 214 base pairs (bp) and 3.5 kb, respectively. The plasmid DNA is likely inside the LNPs and is protected from nucleases.
Conclusion: These data demonstrate the presence of billions to hundreds of billions of DNA molecules per dose in these vaccines. Using fluorometry, all vaccines exceed the guidelines for residual DNA set by FDA and WHO of 10 ng/dose by 188 – 509-fold. However, qPCR residual DNA content in all vaccines were below these guidelines emphasizing the importance of methodological clarity and consistency when interpreting quantitative guidelines. The preliminary evidence of a dose-response effect of residual DNA measured with qPCR and SAEs warrant confirmation and further investigation. Our findings extend existing concerns about vaccine safety and call into question the relevance of guidelines conceived before the introduction of efficient transfection using LNPs. With several obvious limitations, we urge that our work is replicated under forensic conditions and that guidelines be revised to account for highly efficient DNA transfection and cumulative dosing.
You can review the full manuscript yourself by following this link.
Understanding the Science behind this finding.
To follow the technical aspects and meaning of what has been discovered and demonstrated, you need to understand some molecular biology basics. I will do my best to explain and provide necessary context to those who have not had upper division molecular biology university training. I admit to being a little too close to the subject, and sometimes I assume too much background knowledge. If so, my bad. As Professor Richard Feynman is credited with saying, “If you can’t explain something in simple terms, you don’t understand it.” I will try to live up to his standards.
We have to start with the “central dogma” of biology. DNA makes RNA, RNA makes protein. <Yes, of course I know about reverse transcriptase, I was originally a retrovirologist, but lets table that for now please?>
If you want to manufacture large amounts of pure RNA, you basically need to start with large amounts of DNA, and use a protein enzyme (bacteriophage T7 RNA polymerase in my original method, which is still used) plus RNA chemical subunits and a source of energy (ATP) to make RNA from the DNA. Then you need to break down the DNA into small fragments while still leaving the larger RNA intact. Then you need to purify the small DNA fragments from the larger RNA. In my original process, this was done using a type of filter (gel chromatography) which lets the little degraded DNA fragments and the small unused chemical subunits pass through more rapidly than the large RNA molecules. And then you throw away what comes out first – the little stuff (DNA fragments and unused chemicals) and keep the big stuff that comes through later – which is basically pure RNA dissolved in water.
Does that make sense?
Then, once you have that negatively charged purified RNA in water, you can make it more or less concentrated, mix it in fancy ways with other stuff like self-assembling positively charged fats to produce lipid nanoparticles, store it in a glass vial, and inject it into people. And that is the manufacturing process for pseudo-mRNA vaccines in a nutshell.
What could possibly go wrong, you ask?
In this case, at least two things appear to have gone wrong. The first involves the DNA that is used to manufacture the RNA <remember the central dogma of biology?>. And the second involves the DNA degradation and purification process employed <also as discussed above>.
There are apparently two different ways that were used to manufacture the DNA. The original manufacturing process used for the initial clinical trials employed the polymerase chain reaction, which can be and was used to make larger linear fragments of DNA (accuracy is somewhat problematic), which then were used to produce the RNA. This turned out to be too difficult, expensive, time-consuming etc. to support mass manufacturing at the level needed to support worldwide dosing. So apparently Pfizer/BioNTech and Moderna both turned back to the original method which I used, which relied on circular “plasmid” DNA produced using bacteria (special lab strains of E. coli, which bacterium is commonly found in your gut).
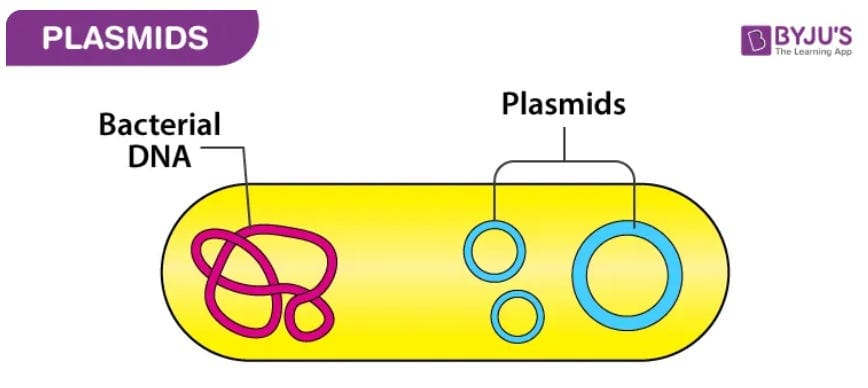
You can think of plasmids as sort of like the purest forms of a bacterial virus. There are other more virus-like things that infect bacteria (called bacteriophage), but plasmids are circular DNA which can literally infect bacteria as pure DNA, and can direct those bacteria to transfer themselves and other plasmids from one bacteria to another.
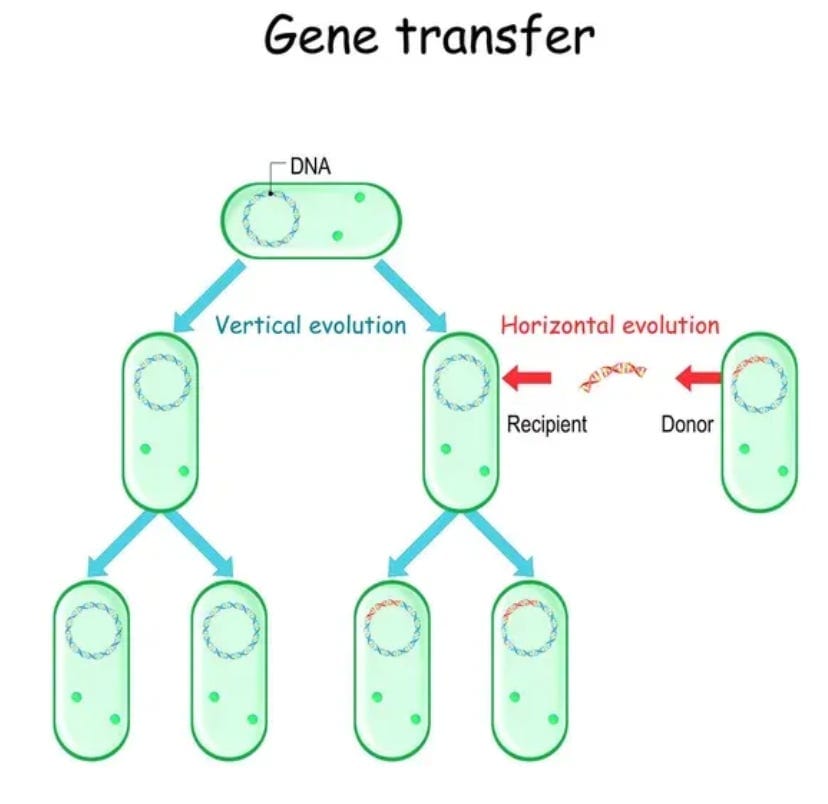
These plasmids are like small parasitic DNA circles which often can help the bacterial host survive better under certain conditions such as exposure to antibiotics, and under those selection pressures the plasmids are maintained by the bacteria because they provide a survival or reproduction advantage. If the plasmid does not provide an advantage, other similar bacteria will outcompete those with the plasmid, because there is a cost to the bacterial host to maintain the parasite plasmid. <Be patient, this is going somewhere which is relevant to the main topic…>.
If you want to grow and recover (ergo manufacture) the most plasmid DNA that you can in a culture of E. coli bacteria, you want to use the smallest, most stripped-down plasmid that can be engineered. Because any extra DNA sequences in the plasmid will come at a price of less plasmid production per liter in the resulting bacterial culture. Therefore you do not want to add DNA sequences into that plasmid that you don’t need for plasmid replication, antibiotic selection (Kanamycin or Neomycin in this case), and eventual RNA manufacturing. Does that part make sense to you?
So why, in heavens name, would any corporation developing and deploying a plasmid-based manufacturing process for large-scale synthesis of RNA from a DNA template include sequences in the plasmid that are not necessary for the intended purpose? Why add sequences lifted from a known oncogenic (ergo, cancer-causing) DNA virus like Simian Virus 40 (SV40)?
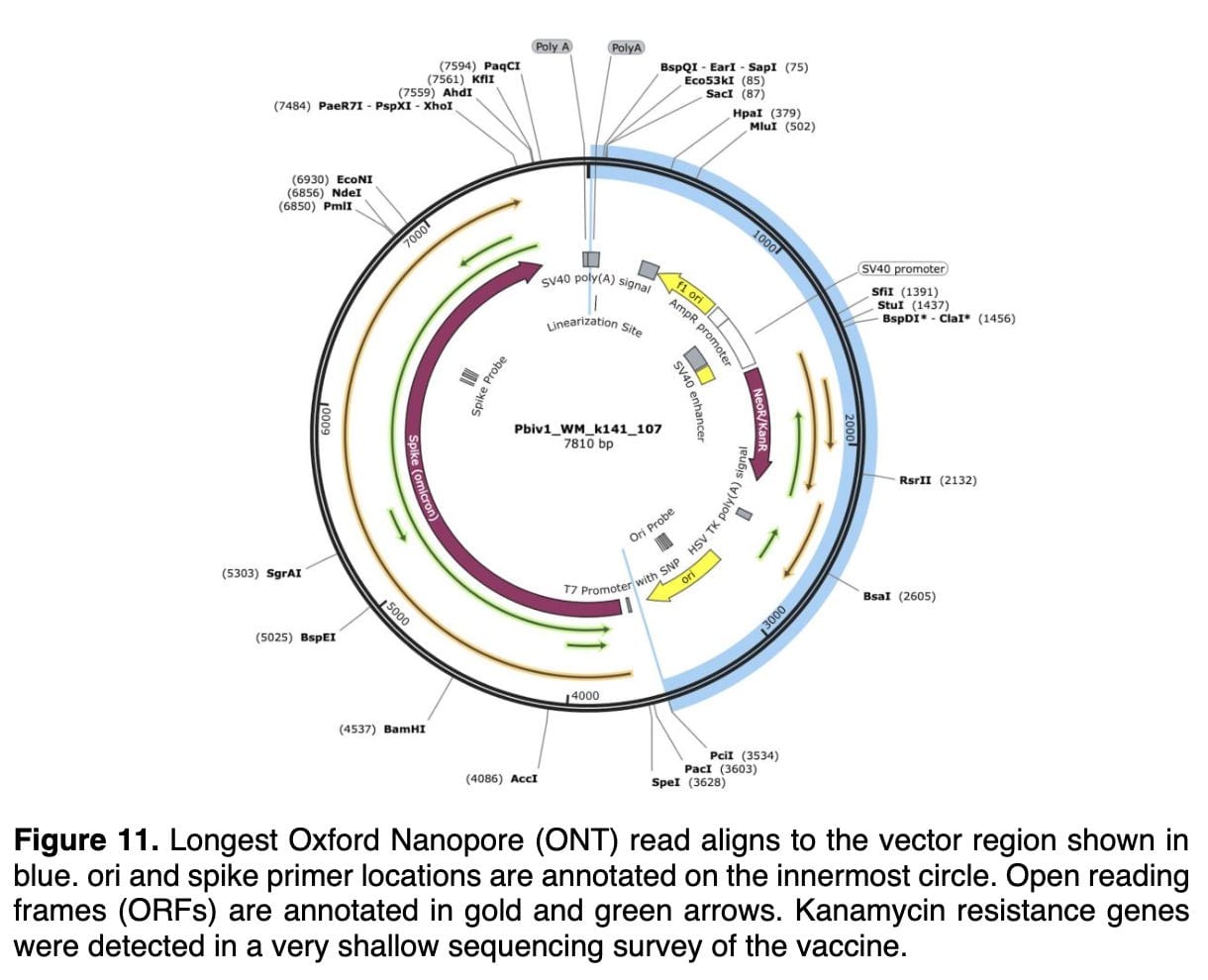
It turns out that these specific SV40 sequences which have been identified in the plasmid DNA fragment contamination documented (above) by Speicher et al are commonly used in a specific type of engineered bacterial plasmid which was developed decades ago for use by molecular biologists. This is well established “common core” recombinant DNA technology.
Bacterial plasmids can and have long been engineered to replicate and produce RNA (and proteins) in both bacteria and in animal cells. Such plasmids are called “shuttle vectors” in the industry. They can be manufactured and purified in large quantity using laboratory E. coli strains, and then transferred (“transfected”) into animal cells where they can replicate for a period of time (under some conditions) and produce the RNA and protein of interest in the animal cells – under the control of promiscuous SV-40 derived sequences in this case.
So what the heck are the SV-40 sequences doing in plasmids whose sole purpose is to be purified and used to produce large amounts of RNA “in the test tube” using a commercial-grade enzyme-based manufacturing process? Good question.
I can speculate or hypothesize, but I suggest that it is the job of Mr. Pharma and Mr. Government Regulator to answer that question. And to address why this was never disclosed to the public, let alone subjected to any formal assessment of possible risks when small fragments of these SV-40 and other plasmid DNA sequences (including antibiotic resistance gene fragments) are delivered into the bodies of patients using the most efficient systemic in-vivo non-viral delivery technology ever developed in the history of the world.
Can I imagine possible risks?
In short, yes. One way or another, at a minimum such fragments are likely to impact on gene expression in the human cells that take up the DNA. One possible impact could involve development of cancers – what molecular biologists and cancer researchers would call transformation (note the emphasis). Should these risks have been investigated before any of this was allowed to proceed and be injected into human beings (without their knowledge)? Of course they should have. And also self-evident is this should all have been disclosed to all concerned. If the FDA, EMA, Paul Ehrlich Institute, Health Canada etc. were not informed, then this would be fraud. If they wereinformed and did nothing, than that would be criminal negligence <in my opinion, but I am an MD, not a JD>.
However, there is an important caveat regarding the SV40 sequences in the Pfizer/BioNTech and Moderna plasmids that is rarely if ever mentioned in the current discussions, which is that the primary mechanism by which SV40 drives development of solid tumors (sarcomas) is the “Large T antigen” protein which the virus produces. The DNA sequences for this protein are NOT present in either of these plasmids.
I predict a hurricane of fact-checker propaganda, obfuscation, and whaddaboutism raised about all of this, but the core facts are indisputable.
Reposted from Substack
Join the conversation:
[Sassy_Follow_Icons social_networks="x=https://x.com/brownstoneinst,facebook=https://www.facebook.com/brownstoneinst,telegram=https://t.me/brownstoneinst, truth_social=https://truthsocial.com/@brownstoneinst, linkedin=https://www.linkedin.com/company/brownstone-institute/, gettr=https://gettr.com/user/brownstoneinst, gab=https://gab.com/brownstoneinst" shape="round" style="background-color:#ac3900;]
Published under a Creative Commons Attribution 4.0 International License
For reprints, please set the canonical link back to the original Brownstone Institute Article and Author.








